The Illusion of Thinking — Part 1
What is thinking, anyway?
Does artificial intelligence think?
And what even is intelligence — natural or artificial?
I started wondering about this more than a decade ago. At some point, I decided to push myself further and took The Teaching of Intelligence (PSYC 310) at McGill — hoping to corner my own ignorance by adding the pressure of knowing. Because, you know, I thought that if I studied hard enough, I’d finally understand something. That I’d find the missing link that would make it all make sense. But just like always, what I found was profoundly human: it’s hard to reduce to one “thing” without losing the meaning.
So, what is thinking?
A sum of processes, maybe. Usually we talk about it as reasoning, applying rules, making deductions, solving problems.
But how is that actually different from what AI does?
Side note: the “emergence” of AI is such a slap in the face to our intellectual ego — and honestly, I secretly love it. We’re being forced into redefinition. It’s an antidote to complacency. Music to my ears. But yes, in the meantime, the struggle is real. lol.
Back to AI.
So, is AI thinking?
So far, AI talks, but there’s no real proof that it’s thinking.
(Reference: The Illusion of Thinking – Apple Machine Learning)
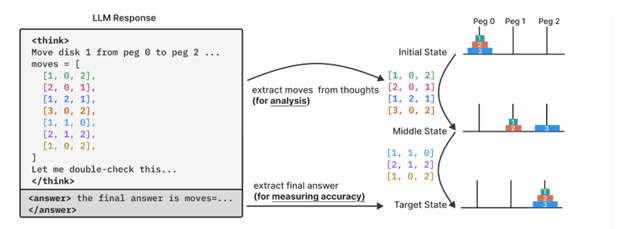
LLMs (Large Language Models — like GPTs) give answers in a human-like way. They produce text that often sounds smart, structured, and confident.
LRMs (Large Reasoning Models — the topic of that paper) go a step further: they’re trained not just to generate text, but to reason — to perform structured, step-by-step logical, mathematical, or symbolic inference. The paper looks at how these steps are performed, and how consistent they are. Basically: how does a model reason through a problem, not just what answer does it end up with?
I find that fascinating. It reminds me why we train neuroscientists to do research — even if most will never actually conduct research after their PhD. You have to understand how things are made in order to trust the conclusions. Otherwise, you risk dumbing yourself down — accepting results that sound right but rest on shaky logic or poorly built studies.
That’s what this paper is about, too: looking not just at the final answer but at the reasoning traces inside the model. In science, same thing — don’t just read the conclusion; look at how the authors got there. Understand how the sausage is made: what steps were taken, and whether the logic holds.
In short, from what I understood:
- LRM (Large Reasoning Models) — which are designed to produce “thinking” traces (step-by-step reasoning) — do exhibit improved performance on certain reasoning benchmarks, but their capabilities and scaling behaviour remain poorly understood.
- LRMs still struggle with big, complex problems. Actually, they collapse a bit — just like LLMs do. Surprisingly, for small problems, LLMs often perform better; for medium ones, LRMs seem to have the edge. In other words, as problem complexity increases beyond a threshold, the LRMs’ "reasoning" effort (token usage, inference steps) actually decreases despite sufficient budget — the model appears to “give up” or fail to engage in deeper reasoning.
- Conclusions (from the authors): “These insights challenge prevailing assumptions about LRM capabilities and suggest that current approaches may be encountering fundamental barriers to generalisable reasoning.”
"Food" for "thoughts".